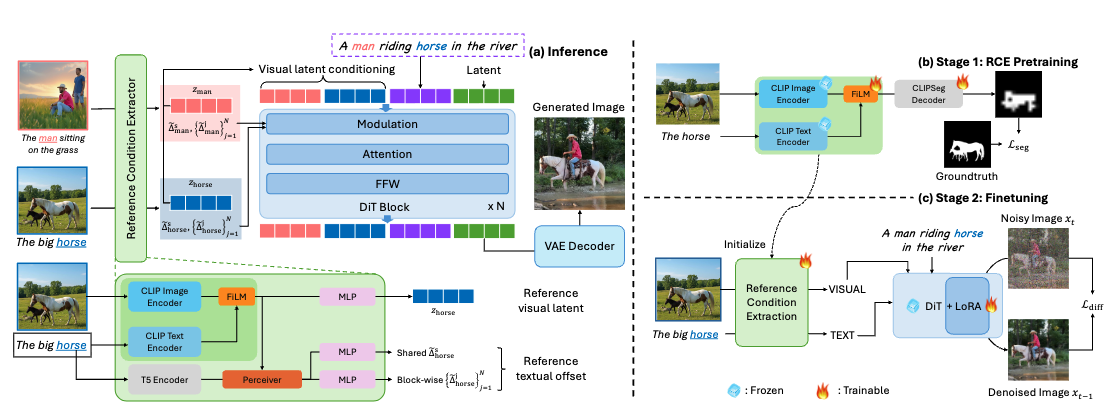
Teaser
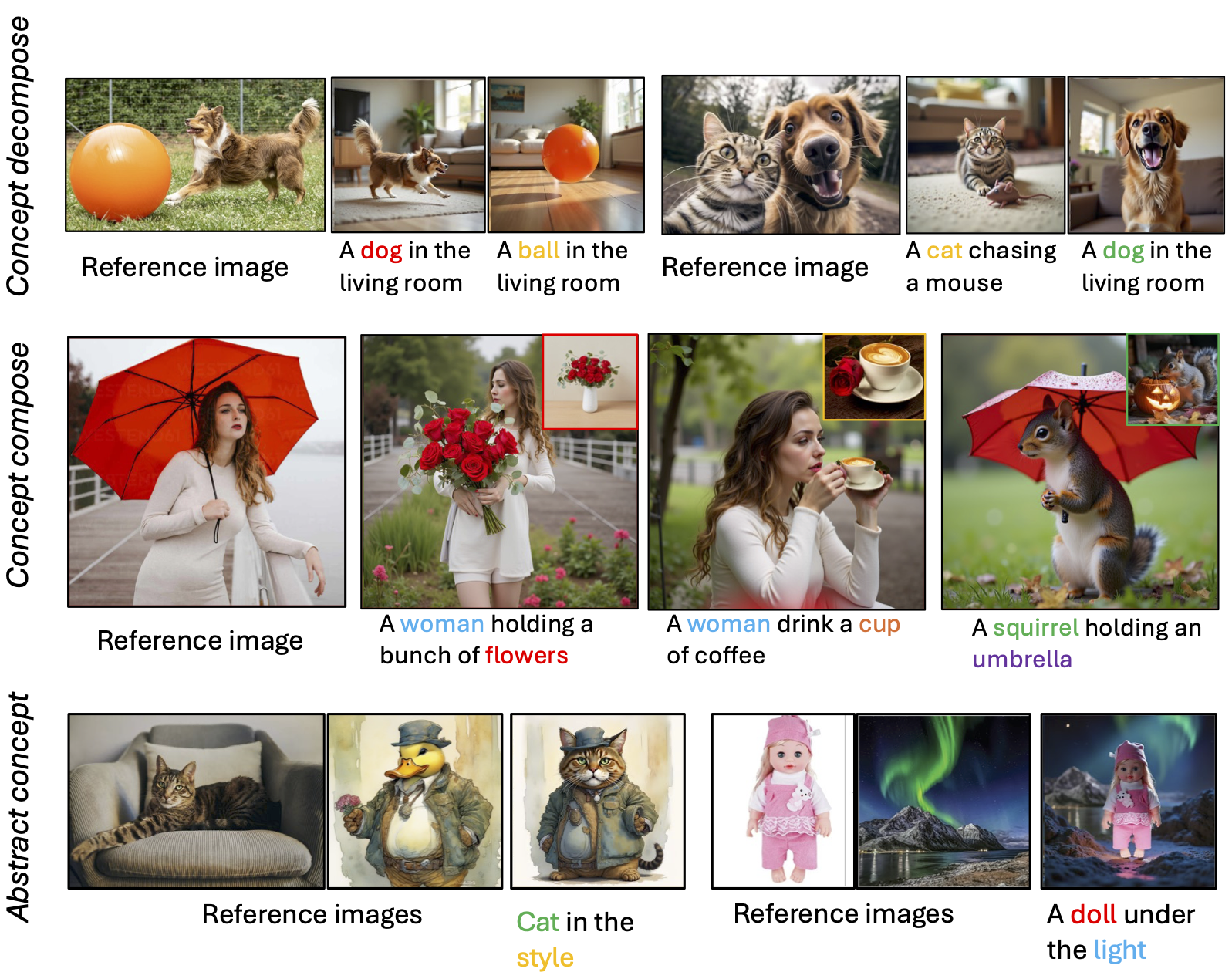
Multi-concept customization with UniVerse. Given a set of reference images and their corresponding text descriptions, our method seamlessly extracts relevant visual concepts and synthesizes new images by composing them, without requiring expensive model finetuning or segmentation. Our approach effectively extracts concepts from objects with partial occlusion or abstract styles, and reliably preserves the distinct identities present in the reference images